Table of contents
Open Table of contents
Multi-agent conversational recommender system (MACRS)
This post walks through a working implementation of MACRS — a Multi-Agent Conversational Recommender System — and extracts the agentic patterns and engineering lessons that generalize far beyond recommendation. The full implementation is available on GitHub.
The starting point was a 2024 paper by Fang, Jiabao et al. I came across it while researching recommendation systems and, after reading the citations and similar work, realized the multi-agent approach wasn’t unique. But the architecture intrigued me enough to build it — and implementing it is where the real learning happened.
What you will learn:
- How to decompose a conversational recommendation task into specialized agents (Ask, Chit-chat, Recommend, Plan)
- How to run independent agents in parallel using
asyncio.gather()to cut latency - How to use dynamic instructions (callable prompts) for turn-specific context injection
- How to implement information-level and strategy-level reflection loops for self-correction
- How to use Pydantic structured output (
output_type,response_format) for safe agent communication - Key agentic patterns: hub-and-spoke, multi-agent act planning, and feedback loops
About Conversation Recommendation System (CRS)
First, let’s start by framing the recommendation problem. We encounter recommendations everywhere: e-commerce, streaming platforms, and even a street vendor suggesting what to buy. Broadly, recommender systems fall into two types:
Sequential Recommendation: “What you’ll probably want next based on your recent actions”- Predicts what you will want next from your recent actions (clicks, views, purchases), modeled as a time-ordered sequence using RNNs, LSTMs, Transformers, or session-based methods.
Conversational Recommendation: “Having a back-and-forth chat to figure out exactly what you want” :Uses multi-turn dialogue to elicit preferences, ask clarifying questions, and refine suggestions based on feedback and context. Incorporates dialogue management, natural language understanding, and interactive preference learning.
Although sequential models learn from history, they often miss what matters right now: mood, today’s context, or a friend’s suggestion. That gap is why recent systems pair LLMs with conversational recommender systems (CRS) to surface ambiguous needs through natural language and produce better-tailored recommendations.
Existing CRS typically fall into two camps. Attribute-based systems ask users yes or no questions about item attributes and respond with templates, but they are rigid: users cannot ask open-ended questions, and the system is limited to hand-written replies. Generation-based systems aim for more natural dialogue but many rely on predefined knowledge graphs or smaller generative models, which limits generalization and makes real-world deployment difficult.
MACRS relies on LLMs and multi-agent planning and memory to generate natural dialogue with the user. More importantly, this is an LLM-only framework in the sense that it does not use an external system to retrieve recommendations. Instead, recommendations come from the LLM’s static memory. This contrasts with CRS approaches that pair an LLM with an external recommender system. In the paper, the use case is movie recommendations. Given a user query for a movie, MACRS aims to provide a successful recommendation, limited by the LLM knowledge cutoff. The system guides the conversation by eliciting user preferences through chat, asking clarifying questions, maintaining a user profile, and learning from recommendation rejections and follow-up clarification.
With that framing in place, let’s look at how MACRS is actually built.
Architecture and Implementation
MACRS (Multi-Agent Conversational Recommender System) is an LLM-only conversational recommender that merges two modules: multi-agent act planning and user feedback-aware reflection. Together they form a continuous improvement cycle. Figure below from the paper shows the overall flow of the architecture.
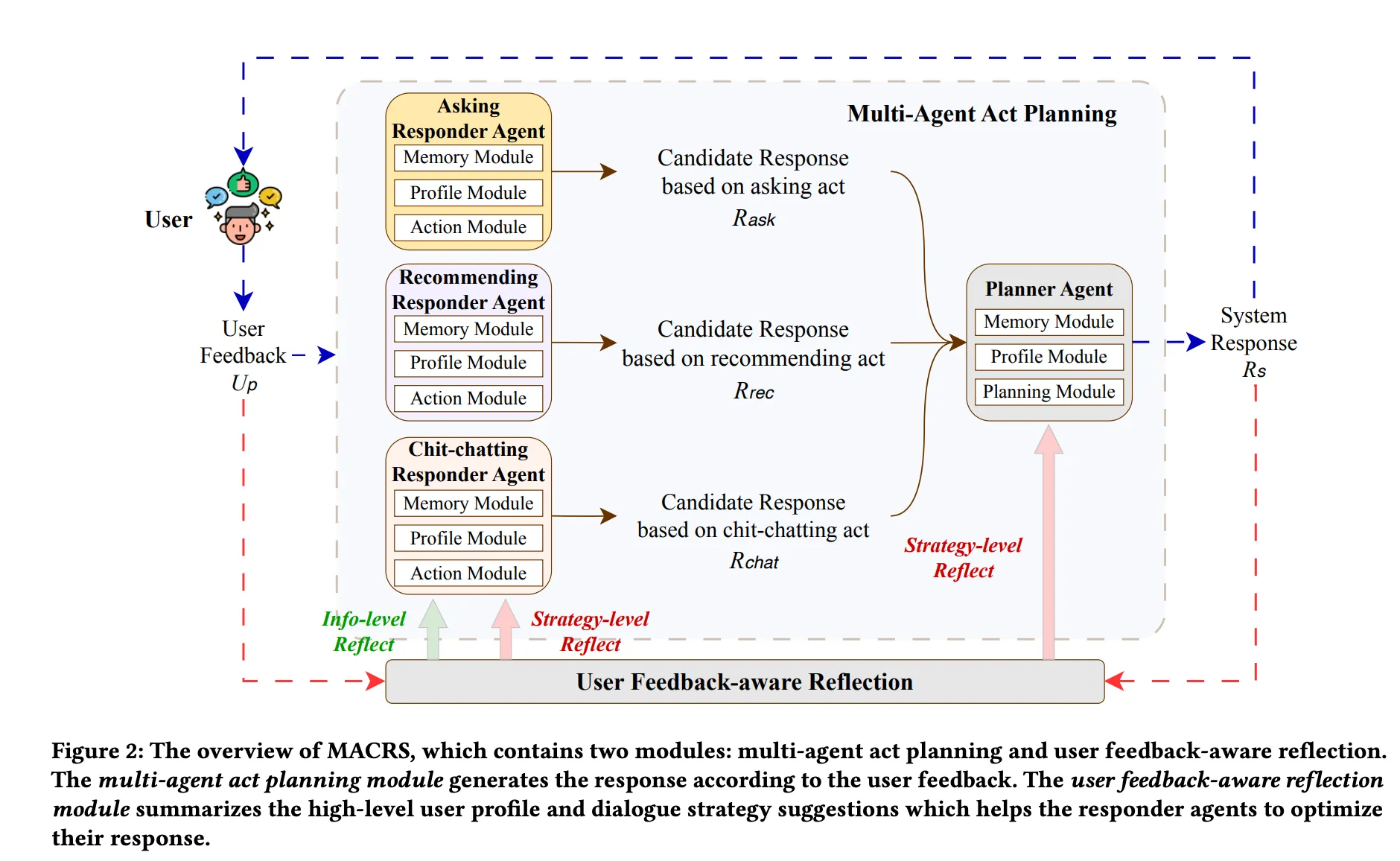 The paper’s architecture diagram: responders run in parallel (left), the planner selects the best act (center), and rejection triggers reflection that updates both the user profile and the strategy for the next turn (right).
The paper’s architecture diagram: responders run in parallel (left), the planner selects the best act (center), and rejection triggers reflection that updates both the user profile and the strategy for the next turn (right).
Module 1 — Multi-Agent Act Planning
The framework includes three Responder Agents and one Planner Agent. On every turn, all three responders generate a candidate response, and the planner selects the best one to send to the user.
| Agent | Role |
|---|---|
| Asking Responder | Elicits user preferences through targeted questions |
| Chit-chat Responder | Maintains engagement with casual conversation |
| Recommending Responder | Generates item suggestions based on known preferences |
| Planner Agent | Hub — reads all three candidates and selects the most appropriate act |
Module 2 — User Feedback-Aware Reflection
A dynamic optimization mechanism that runs in two layers after each turn:
Information-level reflection Runs every turn. Reads the user’s utterances and infers updated preferences — browsing history, current demand — and consolidates them into a user profile. This profile is injected into every subsequent agent call to personalise responses.
Strategy-level reflection Fires only when a recommendation is rejected. Reasons about why the recommendation failed, produces a diagnosis, and writes a strategy suggestion that guides the planner’s act selection in the next turn.
Memory
All agents — both the responder agents and the planner — share state through a single dataclass called AgentsModule. This is the “working memory” of the system for a given turn.
# memory_context.py
@dataclass
class AgentsModule:
turn_count: int = 0
dialogue_act_history: List[str] = field(default_factory=list)
user_profile: Optional[UserProfile] = None
dialogue_history: List = field(default_factory=list)
strategy_suggestion: Optional[Suggestions] = field(default_factory=Suggestions)
asking_agent_response: str = ""
chitchat_agent_response: str = ""
recommending_agent_response: str = ""What to learn here: in multi-agent systems, agents need to share state. The OpenAI Agents SDK uses a RunContextWrapper[T] generic to pass a typed context object into each agent’s instruction function. This pattern avoids global variables and makes dependencies explicit.
The Four Agents and Their Roles
1. AskAgent (ask_agent.py)
Generates one targeted question per turn. Its job is pure information gathering — asking about genre, actor, director, era, mood. It reads strategy_suggestion.for_asking_agent from context to avoid re-asking about things already known and to focus on the most useful attribute gap.
Design principle: one question per turn prevents interrogation fatigue. The planner decides whether to use this response.
2. ChitchatAgent (chitchat_agent.py)
Engages conversationally — like a movie-loving friend — to gather implicit preferences. Rather than asking “what era do you prefer?”, it says “I love how 90s action films had that mix of practical effects and one-liners — does that appeal to you?”. The user’s reaction reveals preference without feeling like a survey.
3. RecommenderAgent (rec_agent.py)
Recommends one movie with a personalized justification. It must:
- Match
user_profile.demand(preferences) - Exclude
user_profile.browsing_history(seen films) - Respect avoidance attributes (e.g.,
director_avoidance: "James Cameron") - Follow
strategy_suggestion.for_recommender_agent(lessons from past failures)
It always commits to a single movie — never hedges with multiple options. The planner decides whether this is the right time to recommend. The recommender always prepares its best suggestion; the planner decides if it’s time to use it.
Each responder agent follows the same pattern: a factory function that creates an Agent[AgentsModule] with dynamic instructions — a function, not a static string.
# rec_agent.py (simplified)
def create_recommender_agent():
def get_recommender_instructions(module: RunContextWrapper[AgentsModule], agent) -> str:
return f"""
User Profile: {module.context.user_profile}
Browsing History: {module.context.user_profile.browsing_history}
Strategy suggestions: {module.context.strategy_suggestion.for_recommender_agent}
...
"""
recommender_agent = Agent[AgentsModule](
name="RecommenderAgent",
instructions=get_recommender_instructions, # ← function, not string
model="gpt-4o-mini",
)
return recommender_agentWhat to learn here: by making instructions a callable, you get fresh, turn-specific context injected into the system prompt at every invocation. The agent’s prompt is effectively a template that renders the live state of the conversation. This is how agents “see” what has happened so far.
4. PlannerAgent (planner_agent.py)
The meta-reasoner. It sees all three candidate responses plus full conversation state, and outputs a structured PlannerResponse:
class PlannerResponse(BaseModel):
reasoning: Optional[str] # step-by-step thinking
decision: Optional[AgentSelected] # ASKING / CHITCHAT / RECOMMENDING
Justification: Optional[str] # why this is optimal for this turnIts decision logic (encoded in the prompt) follows five steps:
- Review dialogue act history — avoid repetitive patterns (ask-ask-ask)
- Assess preference completeness — genre + 2 attributes = enough to recommend
- Evaluate each candidate for informativeness, engagement, appropriateness, efficiency
- Account for turn pressure — at turn 4-5, bias toward recommending
- Apply corrective experiences from past failures
def get_instructions(module:RunContextWrapper[AgentsModule],agent)-> str:
instructions = f"""
You are a dialogue flow planner for a conversational movie recommendation system.
Your task: Select the MOST APPROPRIATE response from three candidate responses
generated by specialized agents.
=== INPUT ===
Dialogue History (last 3 turns):
{module.context.dialogue_history[-3:]}
Current User Profile
{module.context.user_profile}
Dialogue Act History:
{module.context.dialogue_act_history}
Current Turn: {module.context.turn_count} / 5
Three Candidate Responses:
[OPTION A - ASKING]
{module.context.asking_agent_response}
[OPTION B - CHITCHAT]
{module.context.chitchat_agent_response}
[OPTION C - RECOMMENDING]
{module.context.recommending_agent_response}
=== YOUR DECISION PROCESS ===
Step 1: Review Dialogue Act History
- Have we repeated the same action too many times consecutively?
- What's the natural flow progression?
- Are we stuck in a pattern (ask-ask-ask or rec-rec-rec)?
Step 2: Assess User Preference Completeness
- Do we have SUFFICIENT information to make a confident recommendation?
- What critical attributes are still unknown?
- Would asking gather high-value information, or are we stalling?
Sufficient preferences typically include:
✓ Genre clearly specified
✓ At least 1-2 additional attributes (actor, director, era, mood)
✓ Some constraints or dealbreakers identified
Step 3: Evaluate Each Response Quality
For each candidate, consider:
INFORMATIVENESS:
- Will this response likely yield useful preference information?
- Does it address gaps in our knowledge?
ENGAGEMENT:
- Is the response natural and conversational?
- Will it maintain user interest and motivation?
- Does it avoid repetitive or robotic patterns?
APPROPRIATENESS:
- Does it fit the conversational context?
- Does it respect the user's recent feedback?
- Does it align with corrective experiences?
EFFICIENCY:
- Are we at turn 4 or 5? (Urgency to recommend)
- Is this action moving us toward successful recommendation?
Step 4: Make Selection
Choose: ASKING, CHITCHAT, or RECOMMENDING
=== OUTPUT ===
Reasoning:
[Your step-by-step reasoning through the 5 steps above, 3-5 sentences]
Decision: [ASKING / CHITCHAT / RECOMMENDING]
Justification: [1-2 sentences explaining why this choice is optimal for
this specific turn]
=== SELECTION GUIDELINES ===
Choose ASKING when:
- Critical preference gaps exist (no genre, actor, or director specified)
- User gave vague response ("something good")
- Early turns (1-2) when building baseline understanding
- Recent response was too general to narrow options
Choose CHITCHAT when:
- Just asked 2+ questions in a row (avoid interrogation)
- User showed engagement with rich responses (maintain momentum)
- After failed recommendation (rebuild rapport before trying again)
- Have partial info but want to explore adjacent preferences organically
Choose RECOMMENDING when:
- Sufficient preferences collected (genre + 2 attributes minimum)
- Confidence level feels high based on dialogue
- Turn 4 or 5 (time pressure)
- User signals readiness ("Yes, that sounds perfect" / "Exactly")
- Corrective experiences suggest now is the right time
Red flags - DON'T choose:
- ASKING: If we just asked in the last turn (unless user was completely vague)
- CHITCHAT: If we're at turn 5 and haven't recommended yet
- RECOMMENDING: If we only know genre and nothing else (too risky)
=== EXAMPLE ===
Turn: 3/5
Dialogue Act History: [Turn 1: ASKING, Turn 2: CHITCHAT]
Reasoning:
Step 1: We've alternated ASK and CHAT - good variety, not repetitive.
Step 2: We have genre, actor preference, and time period. This is reasonably
sufficient for a recommendation.
Step 3: The RECOMMENDING response suggests "Terminator 2" which aligns well
with all known preferences. The ASKING response would probe about directors,
which could be useful but may delay unnecessarily. CHITCHAT would maintain
engagement but we're at turn 3 with good information.
Step 4: No corrective experiences apply yet (first conversation).
Step 5: With solid preferences and turn 3/5, recommending is appropriate.
Decision: RECOMMENDING
Justification: We have sufficient preference data (genre, actor, era) to make
a confident recommendation, and we're at the midpoint of our turn budget.
Time to test our understanding with a concrete suggestion.
"""
return instructions
planner_agent = Agent[AgentsModule](
name="PlannerAgent",
instructions=get_instructions,
model="gpt-4o-mini",
output_type=PlannerResponse,
)
return planner_agentWhat to learn here: structured output via Pydantic (output_type=PlannerResponse) is critical for agentic systems. Instead of parsing free-form text, the SDK guarantees that the planner’s decision is a typed enum (AgentSelected.ASK / .CHAT / .REC). This makes downstream logic safe and simple.
Parallel Agent Execution
The three agents are independent and run in parallel and generate independent candidate responses. Only the planner — which runs after — needs to see all three outputs.
The three responder agents run concurrently using asyncio.gather():
# main.py
async def gather_agents_reponses(ask_question_agent, chat_agent, recommender_agent,
input_query, agent_module):
tasks = [
asyncio.create_task(run_agent(ask_question_agent, input_query, agent_module)),
asyncio.create_task(run_agent(chat_agent, input_query, agent_module)),
asyncio.create_task(run_agent(recommender_agent, input_query, agent_module)),
]
results = await asyncio.gather(*tasks)
return results # asking, chitchat, recommendingWhat to learn here: when agents are independent (no output of one feeds into another), run them in parallel. This cuts latency by ~3x compared to sequential calls. The OpenAI Agents SDK’s Runner.run() is a coroutine, so it plugs directly into asyncio.
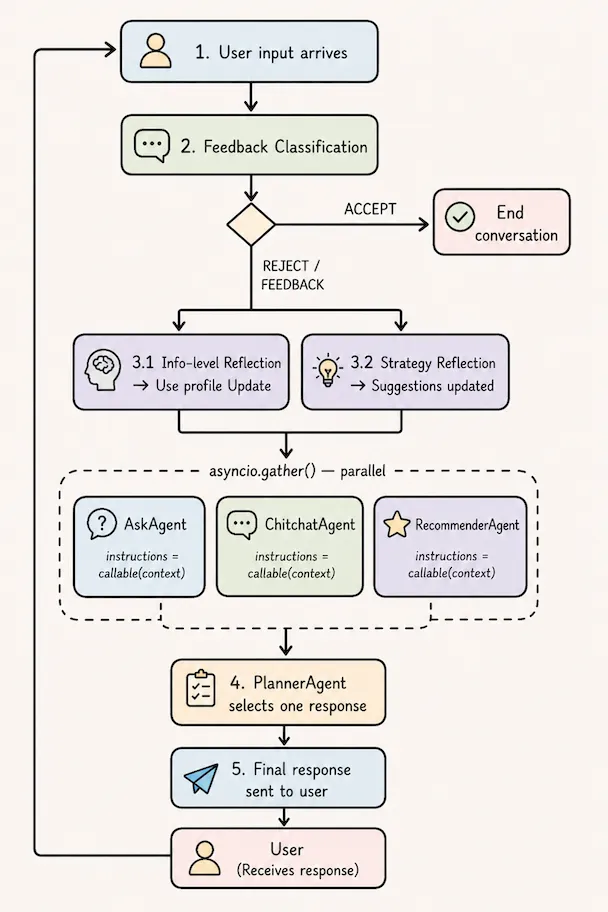 Per-turn execution sequence: feedback classification gates the pipeline, three responders run in parallel via
Per-turn execution sequence: feedback classification gates the pipeline, three responders run in parallel via asyncio.gather(), the planner selects the winning response, and strategy reflection fires only on rejection.
Feedback Classification
Before any of the above logic runs, the system classifies the user’s response to the previous turn:
classify_recommendation_outcome(user_input, system_response)
→ ClassifyFeedback(decision="ACCEPT" | "REJECT" | "FEEDBACK" | "UNCLEAR")- ACCEPT → end the conversation gracefully
- REJECT → trigger error analysis + strategy reflection
- FEEDBACK / UNCLEAR → continue normally, just update the profile
This gate controls whether the expensive reflection pipeline runs. It also prevents the system from continuing a conversation the user has already ended positively.
Reflection and Learning
Information-Level Reflection
After each user turn, run_info_reflect() extracts structured preferences from free-form user text and merges them into the UserProfile:
# reflect_strategy.py (simplified)
def run_info_reflect(user_profile, input_query):
# System prompt instructs LLM to:
# 1. Extract explicit preferences (genre, actor, era, mood, etc.)
# 2. Extract implicit preferences (inferred from phrasing)
# 3. Identify movies mentioned → add to browsing_history
# 4. Merge with existing profile
client = openai.Client()
response = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[...],
response_format=UserProfile # ← structured output
)
return response.choices[0].message.parsed # returns typed UserProfileThe UserProfile stores preferences as key-value pairs, which gives the schema flexibility:
class Preference(BaseModel):
key: str # e.g., "genre", "actor", "director_avoidance", "era"
value: str # e.g., "action", "Arnold Schwarzenegger", "James Cameron", "90s"
class UserProfile(BaseModel):
demand: List[Preference]
browsing_history: List[str]The _avoidance suffix convention (e.g., director_avoidance, tone_avoidance) is enforced through the prompt — the LLM learns to tag negative preferences distinctly from positive ones.
What to learn here: use response_format=PydanticModel (the parse API) instead of free-text generation whenever you need structured data from an LLM. It eliminates fragile JSON parsing and guarantees you get a typed Python object.
Error-Driven Strategy Reflection
When the user rejects a recommendation, the system doesn’t just try again — it analyzes why and generates corrective guidance for all agents:
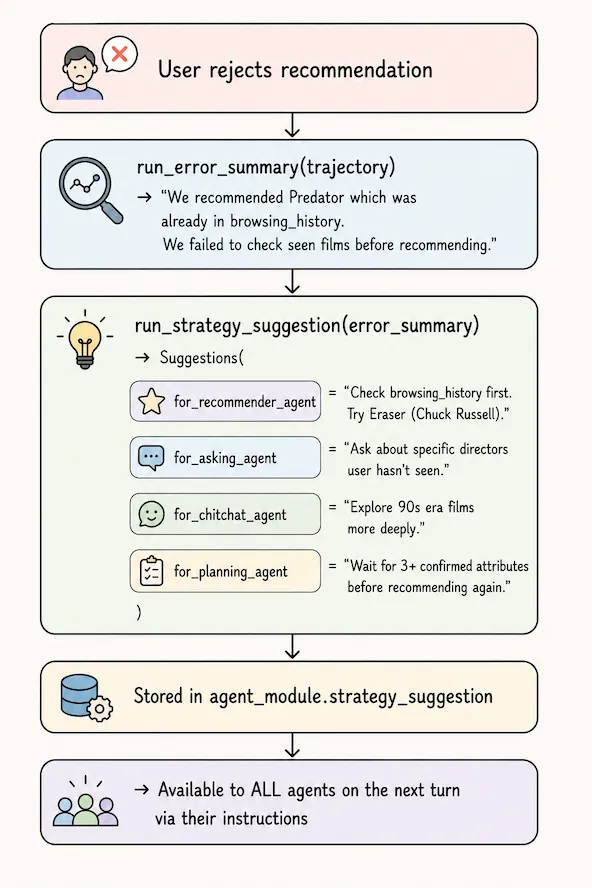
This is the “reflective” component of MACRS. The Trajectory (a list of Turn objects capturing profile + system response + user feedback) is the input to error analysis.
What to learn here: reflection loops are a powerful pattern in agentic systems. By giving the system a way to analyze its own failures and inject corrective guidance back into agent prompts, you get a form of in-context learning without fine-tuning. The key implementation detail is that Suggestions has one field per agent — each agent only sees its own relevant guidance.
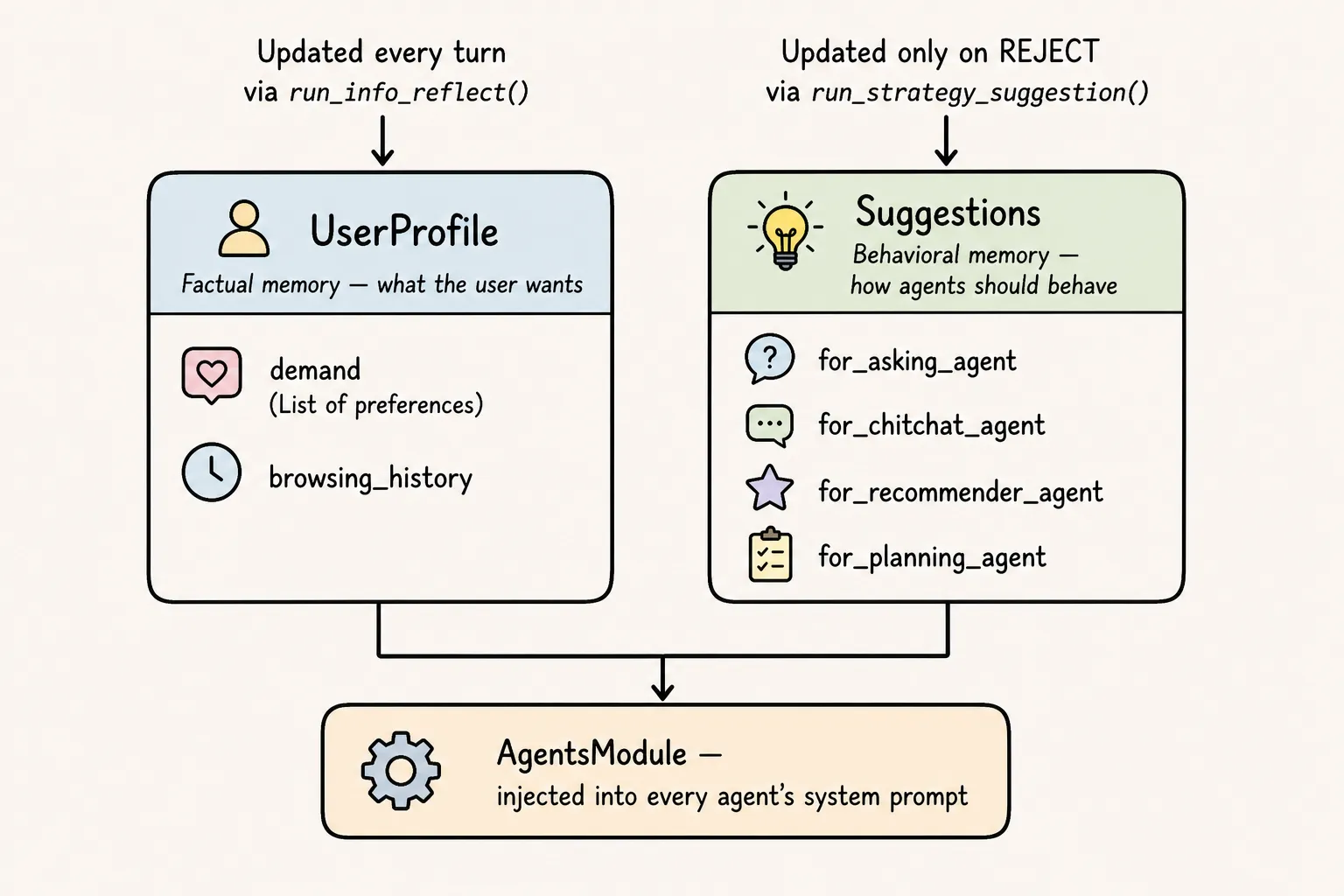 Two distinct memory stores:
Two distinct memory stores: UserProfile captures what the user wants (updated every turn), while Suggestions captures how agents should behave (updated only on rejection). Separating these prevents behavioral guidance from polluting preference data.
Architectural insights and lessons learned
The developer controls how agents are wired together. The agents control what they actually think and say. The architecture’s reliability comes from the former, and its intelligence comes from the latter. Everything the developer assembles before the call is fixed in code. Everything the LLM produces in response is agent-autonomous.
This approach contrasts with a single-orchestrator architecture managing the dialogue flow, where one agent chats with the user, interprets queries and responses, and decides when it has to provide a response.
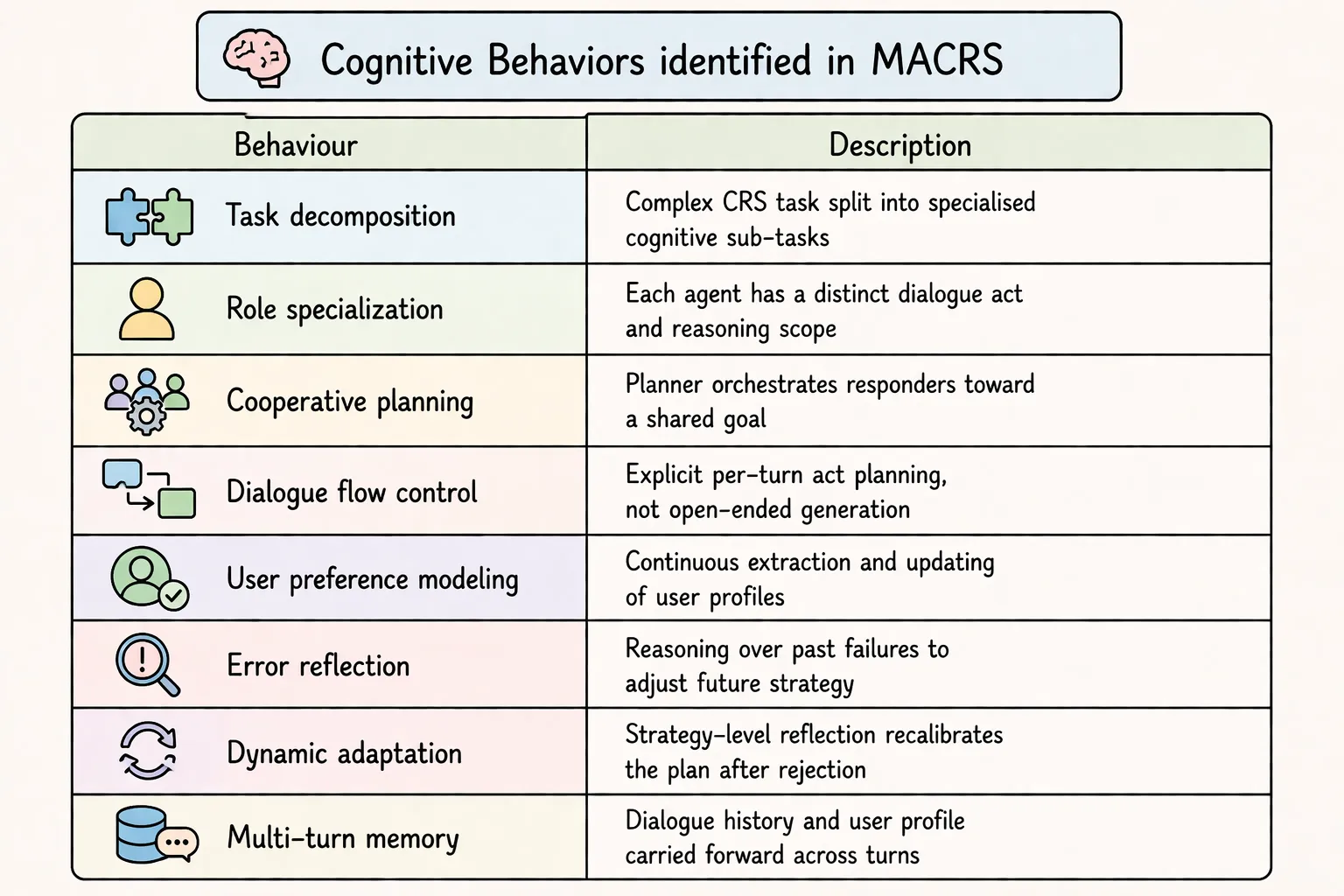
Cognitive Behaviors
The table below shows the cognitive behaviours identified in MACRS.
Agentic Patterns Used
MACRS stacks three distinct patterns, each operating at a different scope.
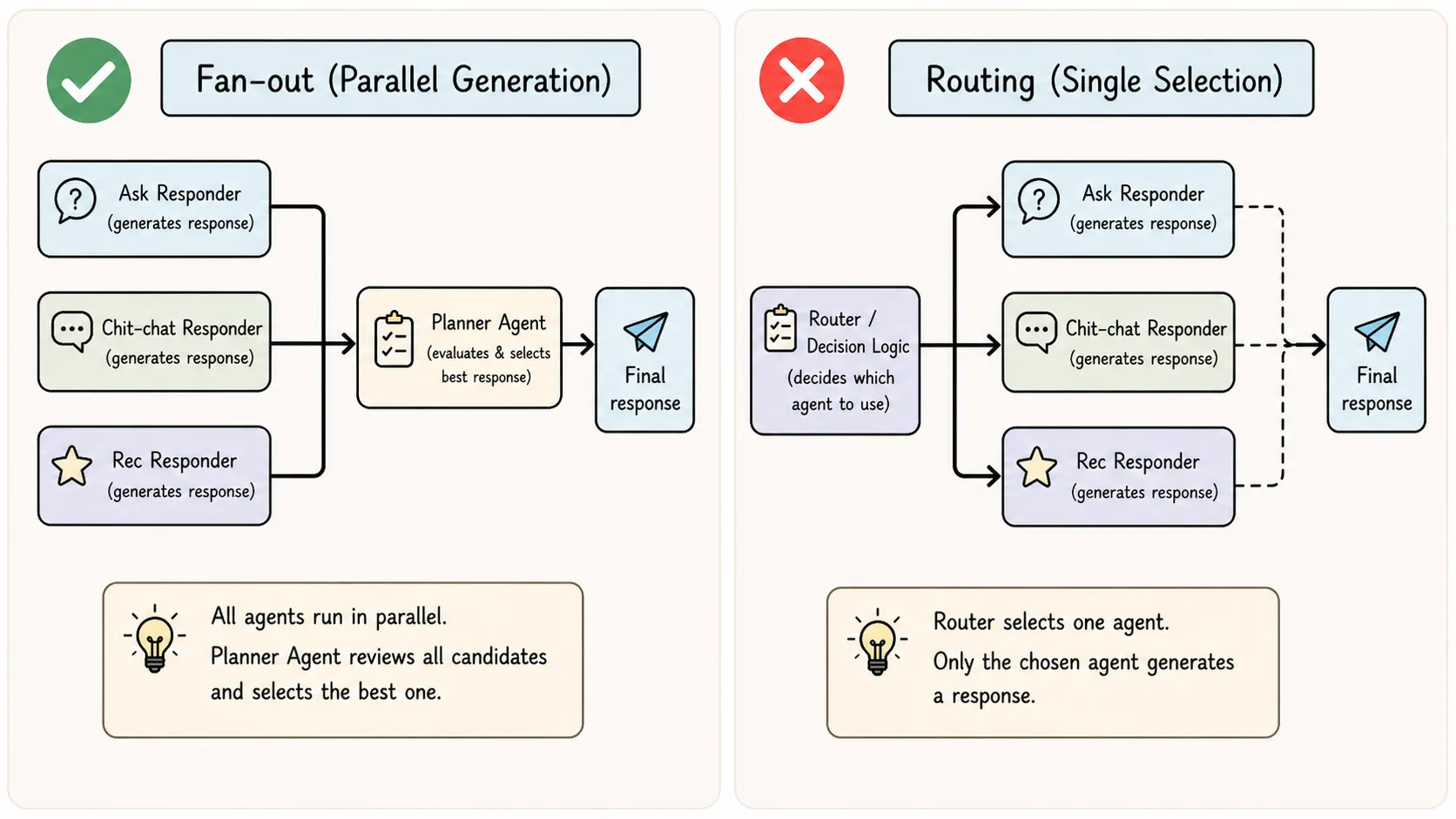
Pattern 1 — Hub-and-Spoke (within a single turn)
The Planner is the hub. The three Responders are spokes. All three spokes are always invoked — the hub fans out simultaneously, collects all candidates, and picks one. Spokes never communicate with each other.
This is not routing (routing sends traffic to one agent or another). This is fan-out + aggregation.
Pattern 2 — Multi-Agent Act Planning (within a single turn)
Layered on top of hub-and-spoke, every turn has two sequential phases:
- Plan — Planner reads dialogue history + user profile + strategy hint and decides which act is appropriate
- Execute — The planner selects one of the three already-generated candidate responses
The planner never generates content. It only reasons about which kind of content should be generated. These are separate LLM calls with distinct prompts and responsibilities.
Pattern 3 — Feedback Loop / Reflection Loop (across turns)
Zooming out to the full conversation, MACRS runs a persistent loop between turns:
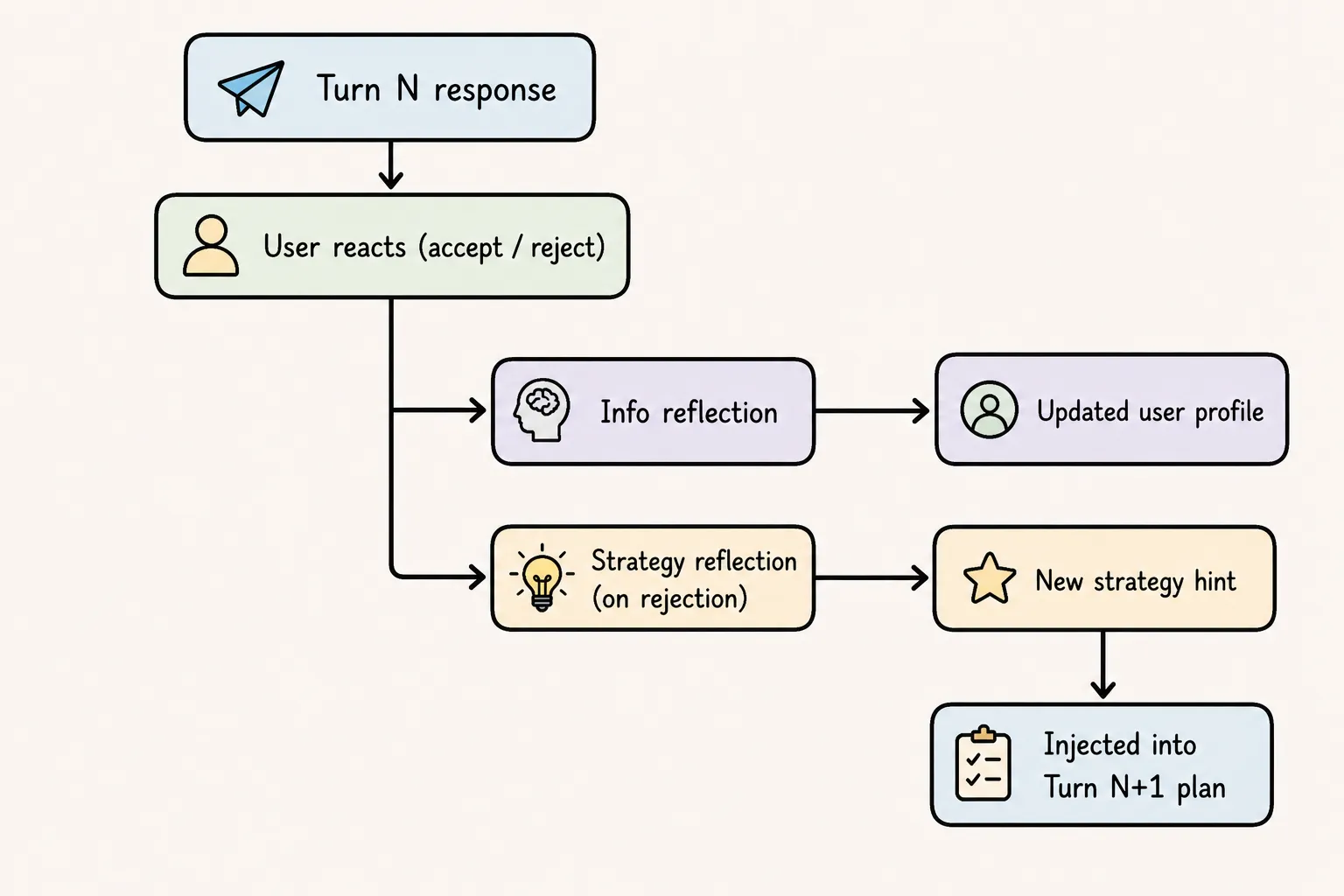
This is what distinguishes MACRS from a simple plan-and-execute: execution outcomes change the plan of the next cycle. This is the self-correction loop pattern.
These three patterns — hub-and-spoke, act planning, and feedback loops — point directly to practical engineering lessons.
Lessons for AI Engineers
These lessons generalise beyond recommender systems to any agentic system.
- Decompose by cognitive role (eliciting vs engaging vs recommending vs planning), not by data type.
- Separate generation from selection (responders draft; planner chooses) to reduce self-evaluation bias.
- Treat failure as signal: rejections trigger diagnosis + corrective guidance.
- Keep two memories: factual state (profile) vs behavioral state (strategy hints).
- Reflect conditionally: cheap extraction every turn; expensive replanning mainly on failures.
- Keep the orchestrator non-generative so errors are attributable (strategy vs content).
- Inject context explicitly instead of letting agents “go look for it”.
- Design the loop first, then fit agents into clear slots.
- Bound autonomy with interfaces (role, inputs, outputs).
- Structure > prompts: performance mainly comes from wiring, not wording.
References
- Fang, Jiabao, et al. “A Multi-Agent Conversational Recommender System.” arXiv, 2024.
- OpenAI Agents SDK documentation